
I may be in the minority, but I actually try to make the most of the communications statistics features in a SCADA system. I have been tracking how many polls, replies, and timeouts are on each of the channels of our SCADA system. For some reason, nobody with any security experience seems to mention how or why this is important. Most people ignore all but the communications failure alarms, and sometimes even that goes unnoticed.
Allow me to rant a bit about setting timeouts. Most people put the defaults in for timeouts without a second thought. The defaults are almost never set for ideal or typical applications. They’re usually set for the worst likely latency and slowest likely communications speed. This is so that the product will work “out of the box,” not so that it might be optimized in any way.
Thus, when telecommunications infrastructure is degraded, everything goes bad very suddenly. I prefer to know as early as possible that things are starting to get ugly. I track what reliability each site has had in the past so that I can determine when they start degrading. This is then forwarded to the telecommunications staff.
Why set the timeout so closely? Because with tight timeout settings, one can notice changes in latency. This is a strong indicator that someone has changed things in the underlying network.
In one case, our telecommunications staff changed how an RTU reports back to the master. They routed it through a data repeater. This caused the response time to double. Naturally, because they didn’t tell us, it didn’t work. I had to nearly double the timeout time, and it began to work. This caused them to realize the impact on the rest of the SCADA system. It made them aware of why we don’t do this everywhere. So they learned useful information as well.
In addition to timeout ignorance, most have no idea of what to expect from a scan cycle. Again, I’m going to cite the DNP3 standard, but you can apply these sorts of concepts to many other protocols.
A single FT3 frame will not be any longer than 292 octets (bytes) long. It is possible for the frame to be shorter, though. However a single frame is a good size for a timeout because it is a convenient and efficient unit of time and data to acknowledge.
If you figure a single start and stop bit in to the picture, that’s 2920 bits. Divide the number of bits by the data rate (9600 BPS for example) and you will get 305 milliseconds. This is what I would consider a bare minimum timeout. To that, you should add any overhead for sending the poll message through a serial port server, network latency and possibly the outbound poll (more on this ahead), and with all that you could reasonably set the timeout to about 350 milliseconds. (In North America many MAS radio channels use 12.5 kHz channels with GMFSK modulation running at 9600 BPS, so this example is actually quite typical)
Knowing how many messages will fit in a given period of time, you can now design a full round robin scan cycle. How many RTUs can you poll in how many seconds? How much slop should you allow in there for scan cycle interruptions from commands, retries and the like?
Now consider a retry. The master polls, it gets a response. It polls, it gets a response. It polls and this time it doesn’t get the whole thing. It times out. Then it asks again. This time the remote responses appropriately. How much time does a retry cost? One Full Timeout. For that reason, we try to set our timeout timers pretty tightly. Long sloppy timeouts lead to long sloppy scan cycles.
So now that you know what a retry costs time-wise, be sure to set the retry counter reasonably. One retry might be appropriate, but more than that is usually an indication that things are broken. A second retry might be added as a stopgap measure, before someone can get to the site and service it, however, it is not a good idea to leave things that way. Remember that a link reinitialization transaction is relatively short, and that’s pretty much all you’re saving. Too many retries can lengthen scan cycles considerably when communications are degraded. Other protocols are slightly different, but in general, if you have more than one retry set, you’re probably doing something poorly.
You might wonder why I’m obsessed with communications degradation. On radio SCADA systems, sooner or later, one will encounter problems with radio paths, with interference, or with hardware failures such as a wet connector near the antenna. We should expect our SCADA system to perform reasonably even in the face of degraded communications. The trick is to keep latency low, packet sizes reasonable, and retries to a minimum. Personally, I prefer to keep everything down to one FT3 frame, though there are a few stations that allow for longer messages.
So how well is the polling scan cycle doing? To figure that out, watch in a given period of time (say a five minute period), for how many outbound polls and inbound responses the master received. Did it total up reasonably? How did the whole channel do? How well did each RTU do? What is the success rate of each RTU?
If you do this, you can spot trends where communications degrade before they become a problem. Knowing this, one can send telecommunications staff to a site before things are completely broken. Common problems with the antenna and transmission line can be dealt with in good weather instead of waiting for complete failure during a bad storm when nobody will be able to do much about it. In other words, this corrective maintenance can have scheduled down-time instead of unscheduled down-time. The Operations staff will thank you.
To do this, in a given period of time, measure how many messages an RTU received from the Master station and how many messages were sent to the Master. The RTU sends that information back to the master. This way we can get early warning of problems that might not manifest themselves right away.
The Master also does those same same counts for each RTU in each period. Then compare the results. Did the remote see ALL the messages from the Master? It’s okay to see less (the radio link might be marginal, after all). But did you happen to see MORE messages than the Master sent? If you saw more than the master sent, that’s a sign that your RTU is hearing another Master. Is that Master yours? Maybe someone is messing with you.
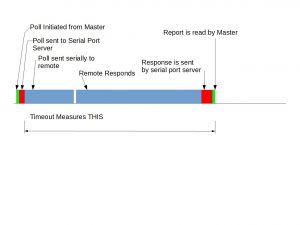
This brings us back to the timing issue: When does the timeout timer start for the Master software? If the Master starts the timer after sending a message to a serial port server, you’ll have to account for the time it takes to actually sends the poll. That poll may be around 20 to 30 octets long, depending on exactly what sort of poll you’re sending. The Master only knows when the packet was created and sent to the serial port server. The actual sending over the air is not accounted for.
Furthermore, the master may only count a message from the remote after it was correctly received. This could be on the other side of the time measurement period. Thus, you may see mis-alignments of one message due to what is commonly referred to as a “fence-post” error.
So now we know how fast the polling should work. Let’s allow for a few retries, and then don’t forget the command that interrupt this cycle. How long does a complete poll cycle take? This is also an indication of how well the SCADA system is doing overall.
Surprisingly, Poll Cycle times are very regular. In a given period on our SCADA system, we see variations of up to 10% from our expected number of polls, but not much more. Track how long a poll cycle takes. If you see wide variations, there is something interesting going on. It is worth trying to find out what.
But here comes the zinger: If you know what the total number of polls in a given synchronous time period is supposed to be, and you look at how many each RTU reported during that same period, you can get two things:
First, your RTU can tell you how well it hears the master. The percentage of polls received should be about 98 percent (on the low end) to 100 percent of all polls sent. However you should not see more than what the master sent. If you do, there may be fence post counting errors with sending and receiving messages. Thus it is imperative that you understand precisely when a message gets sent and when it is counted at the other end.
Here’s the big deal: By watching the scan period time, the number of retries in a time period, the number of messages received by each RTU and the number sent by the Master, the number sent by each remote and the number received by each master, you can know a lot about how your SCADA system is performing. If you see anomalies, you’ll know right away where to look and you’ll know when they are likely to be communications failure issues instead of a hack.
No, it won’t tell you “I’m being hacked.” But it will let you know what a likely random failure is, versus some sort of possible security issue. And that’s as good as security gets in this business.
Next, I’m going to discuss how this looks on a WAN. Where are the various elements of your SCADA infrastructure, what do they do, and why do you care? Stay tuned.